The internet is no longer human-only. Today, automated traffic is growing faster than human, and the composition of that traffic is changing fast. Automated traffic now includes not just traditional scraping bots, AI-driven bots like training crawlers, real-time retrieval scrapers, autonomous AI agents, and agentic browsers—each with different purposes, behaviors, and risk profiles. For publishers and other content-driven digital platforms, understanding the differences between these categories is essential to managing them effectively. Some AI-driven scraping is welcome—it can surface your brand in LLM-generated answers, drive agent-assisted commerce, and expand your reach. But not all of it is authorized, and without visibility and control over what’s hitting your site, organizations can’t distinguish between the traffic that creates value and the traffic that extracts it.
Understanding AI-driven scraping bots: crawlers, scrapers, and AI agents
Before looking at how to manage AI traffic, it helps to understand the distinct categories of automated systems hitting your site. Not every “AI bot” is intelligent—and lumping them together leads to blunt controls that miss the point. HUMAN distinguishes between three core categories:
LLM training crawlers
LLM training crawlers (such as GPTBot, ClaudeBot, and PerplexityBot) systematically collect web content to build and improve the datasets that power large language models. There is nothing inherently “AI” about how they operate—their methods resemble those of conventional web crawlers, but their purpose is to feed content into AI training pipelines.
Responsible crawlers will identify themselves via their user agent strings, allowing organizations to decide whether to allow or block them. The challenge arises with crawlers that may not declare themselves or actively try to obfuscate their intention to scrape information.
The scale of unauthorized scraping has triggered a legal reckoning: more than 70 copyright infringement lawsuits have been filed against AI companies, and in late 2025 alone, The New York Times and Chicago Tribune sued Perplexity, Penske Media became the first publisher to sue Google over AI Overviews, and 14 major publishers won a first-round ruling against Canadian AI startup Cohere. Many of these crawlers continue to scrape aggressively while ignoring robots.txt (a file that contains instructions for bots on which pages they can and cannot access).
RAG and real-time retrieval scrapers
Unlike training crawlers that collect data in bulk for future use, RAG (Retrieval Augmented Generation) scrapers operate on demand, fetching content in real time to answer specific user queries. When someone asks ChatGPT or Perplexity about current events, these systems deploy retrieval bots (such as ChatGPT-User, Perplexity-User, or MistralAI-User) to fetch information from authoritative sources and incorporate it into their responses.
For example, you could ask an LLM “What is the latest news in my area?” and it will perform a search, scrape the results, and return a summary—all without the user ever having to visit the source application. In addition to potentially taking that information without permission, sometimes the provided summary is taken out of context or is factually incorrect, which compounds the problems associated with content scraping, as now misinformation is added to the mix.
AI agents and agentic browsers
AI agents represent the most sophisticated category of AI-driven traffic. These are autonomous systems that can reason, plan, and execute complex multi-step goals on behalf of users—browsing websites, filling forms, comparing products, and even completing purchases. Unlike scrapers and crawlers, agents interact with your site the way a human would, using automation frameworks like Playwright and Puppeteer to simulate mouse movements, clicks, and keystrokes.
HUMAN telemetry shows that AI agent traffic grew over 6,900% year-over-year in 2025, with particularly sharp acceleration during high-intent commercial periods. During Black Friday/Cyber Monday 2025, agent traffic to e-commerce sites surged 144% from its pre-holiday baseline, and more than 83% of that traffic targeted product and search pages.
Performance impact
Large-scale scraping can also negatively impact web application and site performance. This can result in a poor experience for users, loss of revenue or, in extreme cases, denial of service. Scraping bots can also boost invalid traffic (IVT) rates by viewing ads as they crawl an application, devaluing your ad space.
The spoofing problem: Not all AI traffic is what it claims to be
Managing AI traffic is further complicated by the fact that a significant share of it is spoofed. HUMAN’s Satori Threat Intelligence team analyzed traffic associated with 16 well-known AI crawlers and found that 1 in every 18 requests using an AI crawler user agent is fake. Attackers regularly impersonate legitimate AI crawlers like ChatGPT-User, MistralAI-User, and Perplexity-User to disguise unauthorized scraping campaigns and bypass security controls.These are not unsophisticated attacks. High-end spoofing campaigns use techniques like IP proximity deception—routing traffic from IPs just outside the official ranges of legitimate crawlers—and serverless function orchestration to distribute scraping across thousands of low-volume IPs. HUMAN Sightline successfully blocked 99.89% of spoofed traffic in the research period, preventing it from reaching customer applications. Read the full Satori research on AI crawler spoofing.
The challenges of using robots.txt to manage AI-driven scrapers
The robots.txt file has long been a standard for managing web crawlers, but its limitations are increasingly evident with AI-driven scraping bots. Many LLMs and their scrapers do not identify themselves, making it hard for website operators to block them effectively. Others may change their user agents frequently as they update scrapers, which can inadvertently cause headaches in blocking their access.
The robots.txt file’s 500 KB size limit also poses challenges for organizations managing complex content ecosystems, especially as the number of AI scrapers grows. Manual updates to accommodate every bot quickly become untenable.
For large crawlers like Googlebot and Bingbot, there is currently no way to differentiate between data used for traditional search engine indexing—where publishers and search engines have an implicit “agreement” based on citations to the original source—and data used to train or power generative AI products. This lack of granularity forces publishers into a difficult position, where blocking Googlebot or Bingbot entirely to prevent data usage for generative AI also hurts search engine results.
And as our spoofing research demonstrates, even when crawlers do identify themselves, user agents alone cannot be trusted. Effective management requires network-level verification — checking each request against the crawler’s published ASN and IP ranges, not just the user agent string.
How HUMAN helps
HUMAN makes it easy to identify and manage AI-related traffic. As the trust layer for the AI internet, HUMAN provides the visibility, control, and adaptive governance organizations need to make informed decisions about every type of AI-driven traffic—from training crawlers and RAG scrapers to autonomous agents and agentic browsers. Customers can choose from four primary response options:
Block all LLM bots by default
HUMAN blocks LLMs by default to ensure that Publishers are protected from unwanted scraping and theft of their proprietary content. HUMAN’s industry-leading decision engine uses advanced machine learning, behavioral analysis, and intelligent fingerprinting to block scraping bot traffic at the edge, often before they can access a single page. HUMAN will allow bots to access your application only if you have specifically allowed them to do so.
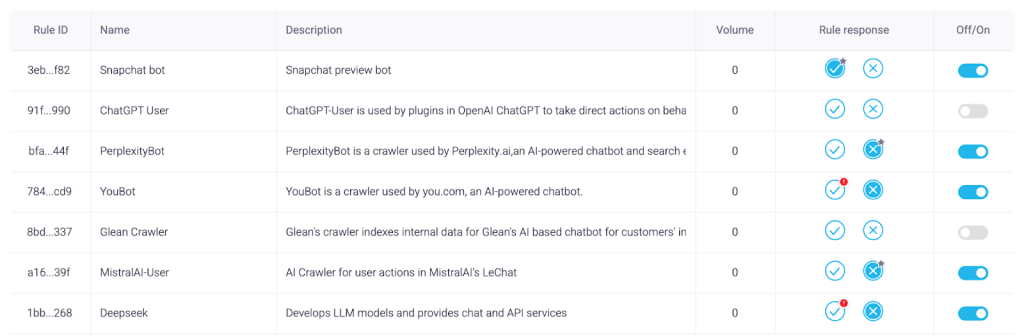
Allow known AI bots and crawlers
Customers can choose to allow trusted bots to access their content unimpeded. With an easy Off/On toggle, users can easily make quick decisions on allowing or blocking AI traffic. This adds a layer of enforcement to your robots.txt file, which is sometimes ignored by LLM scraping agents. If you choose to allow the scrapers, you can also set up custom policies to suppress ads or show alternative content.
Monetize LLMs on a per-use basis
If an AI bot is detected that is not on the customer’s allow list, HUMAN allows the option to send that bot to TollBit’s scraping paywall. There, you can set and enforce payment policies that require bots to pay per scrape. This enables publishers to prevent unauthorized AI agents from scraping their proprietary content unless they provide fair compensation.
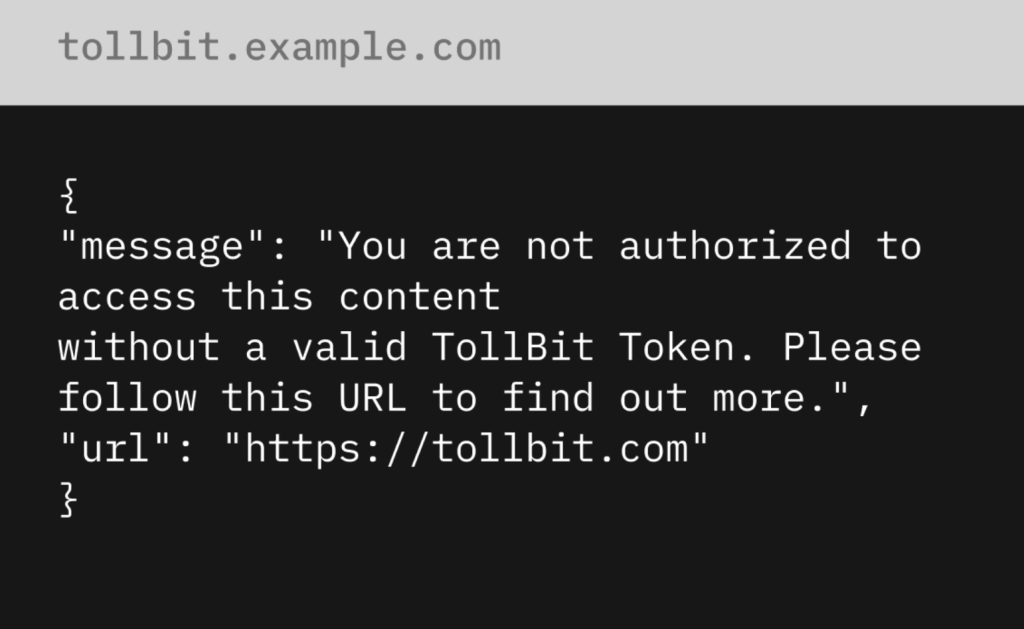
HUMAN’s integration with TollBit transforms the scraping challenge into a revenue opportunity. HUMAN’s detection engine identifies and classifies scraping traffic, then TollBit’s bot paywall is served directly to AI agents, providing a mechanism for AI companies to discover and access content appropriately while compensating publishers. Customers can negotiate scalable licensing deals based on factors like usage type, developer client, publish date, and more. Learn more about the HUMAN and TollBit partnership.
Govern AI agents with AgenticTrust
For the growing share of traffic from autonomous AI agents and agentic browsers, HUMAN offers AgenticTrust—a purpose-built module within HUMAN Sightline Cyberfraud Defense that provides session-level visibility and adaptive governance over agent-based activity.
Rather than treating agent traffic with a simple block-or-allow decision, AgenticTrust enables organizations to verify agent identity (including cryptographic verification for agents that support it), classify behavior as sessions unfold, and enforce granular, action-based controls. You can allow a verified agent to browse and discover products while preventing it from creating accounts or completing purchases—and set different rules for different agents.
This matters because blocking agents outright increasingly means blocking potential customers. HUMAN’s data shows that agent-driven product recommendations convert at 4.4x the rate of traditional search. The organizations that thrive in the agentic era will be those that govern agent traffic rather than simply refuse it. Learn more about AgenticTrust.
HUMAN provides visibility into AI bots and agents
Traffic from known bots, crawlers, and AI agents is automatically highlighted in HUMAN activity dashboards, and the system notifies you if new bots are present on your applications. This makes it easy for organizations to understand the volume of traffic hitting their applications and websites, as well as a granular breakdown of which bots are contributing to the traffic, and to what degree.
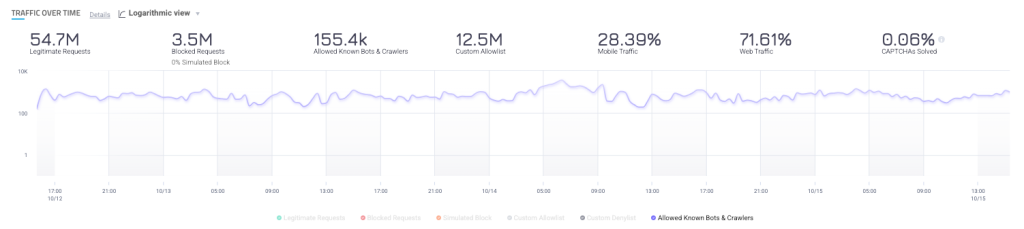
HUMAN also surfaces information about which bots and AI agents are accessing your content and what paths they are targeting. This allows publishers to monitor impacts and make informed decisions to protect your assets.
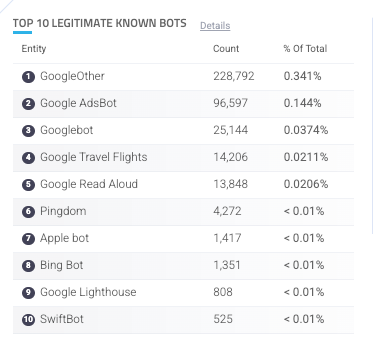
With AgenticTrust, this visibility extends deeper into AI agent sessions. Security and fraud teams gain continuous, real-time monitoring of agent behavior across the full customer journey, including reporting and analytics on which agents are visiting, what actions they’re taking, and which routes they’re targeting most. HUMAN’s detection leverages layered, context-aware signals — correlating network properties, browser authenticity, execution environment artifacts, interaction behavior, and session evolution — to distinguish between human users, benign automation, and autonomous agents even as implementations evolve. Read more about HUMAN’s AI agent detection methodology.
Effective strategies to combat AI-powered scraping
Keeping an up-to-date robots.txt file is a strong first step to manage legitimate bots and crawlers—but robots.txt alone is no longer enough. Organizations need granular visibility into AI scraping activity and complete control to respond in a way that works for their unique business.
The challenge is no longer just identifying threats. It’s deciding who—and what—gets to act, and how much trust to extend at every moment. In a world of mixed actors, the old binary of “human or bot” doesn’t give you enough to go on. You need to understand intent, context, and legitimacy.
That is why HUMAN approaches AI traffic management through a visibility-first model: observe what’s hitting your site, understand the intent and behavior behind it, and then enforce policies based on what the traffic actually does—not just where it comes from. AI traffic isn’t simply “good” or “bad.” A blanket ban blocks real benefits like agentic commerce and brand visibility in LLM-generated answers. Simply allowing everything opens you to abuse. The right approach is contextual governance. Learn more about how HUMAN thinks about trust as infrastructure for the AI internet.
With HUMAN Cyberfraud Defense, you can see exactly how much AI scraping is hitting your site.
Request a free demo and see:
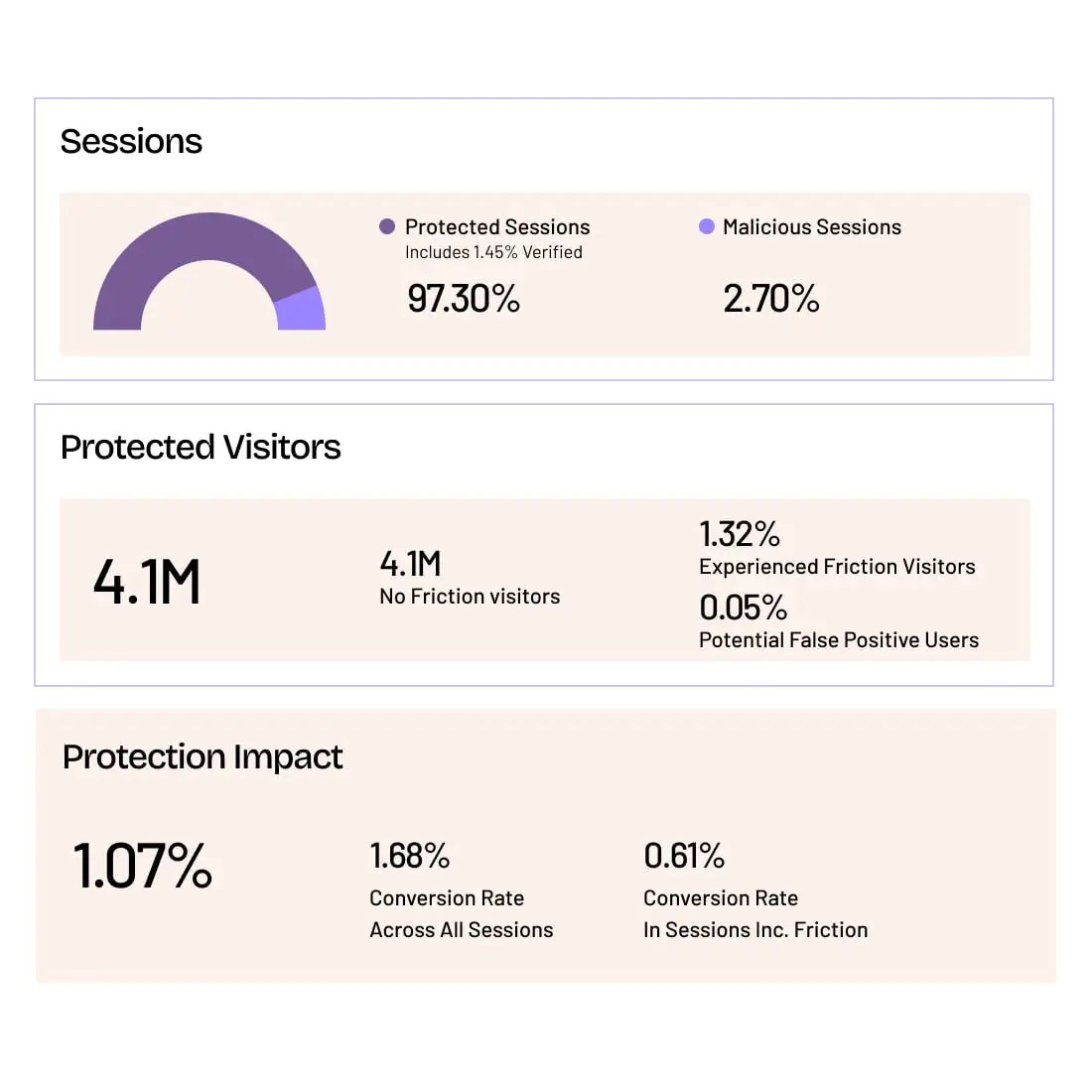
Grow with Confidence
HUMAN Sightline protects every touchpoint in your customer journey. Stop bots and abuse while keeping real users flowing through without added friction.