Controlling AI-driven content scraping with HUMAN
Read time: 5 minutesAlexa Levine
Artificial intelligence has become a hot topic in the cybersecurity industry. We have seen instances of AI-powered technology contributing to cyberattacks, but there is still so much more to discover about how it will manifest in future criminal activity. However, there is one area where generative AI—particularly large language models (LLMs)—is already making a clear mark: content creation and summarization.
In the process of creating and summarizing content, generative AI platforms rely on extensive automated scraping from entities across the web. For content-driven digital platforms, scraping by AI agents is often unwanted at best—and copyright infringement at worst.
Understanding AI-driven scraping bots
Content-driven platforms face several types of unauthorized scraping by AI agents:
AI agents scraping content to summarize a response. AI agents use bots to scrape web content to return a response to user queries. For example, you could ask the LLM ChatGPT “What is the latest news in my area?” and it will perform a search, scrape the results, and return a summary—all without the user ever having to visit the source application. In addition to potentially taking that information without permission, sometimes the provided summary is taken out of context or is factually incorrect, which compounds the problems associated with content scraping, as now misinformation is added to the mix.
Scraping of content to train LLMs. LLMs are essentially a giant knowledge base, and they can grow only by being fed more information. AI developers sometimes use scraping bots to capture information from websites to feed the beast. Responsible LLMs will identify themselves, allowing organizations to decide whether to allow or block them. The challenge arises with AI agents that may not declare themselves or actively try to obfuscate their intention to scrape information. Recent articles have shown that some new AI players are scraping even more aggressively while ignoring robots.txt (a file that contains instructions for bots on which pages they can and cannot access).
Performance impact. Large-scale scraping can also negatively impact web application and site performance. This can result in a poor experience for users, loss of revenue or, in extreme cases, denial of service. Scraping bots can also boost invalid traffic (IVT) rates by viewing ads as they crawl an application, devaluing your ad space.
The challenges of using robots.txt to manage AI-driven scrapers
The robots.txt file has long been a standard for managing web crawlers, but its limitations are increasingly evident with AI-driven scraping bots. As mentioned above, many LLMs and their scrapers do not identify themselves, making it hard for website operators to block them effectively. Others may change their user agents frequently as they update scrapers, which can inadvertently cause headaches in blocking their access.
The robots.txt file’s 500 KB size limit also poses challenges for organizations managing complex content ecosystems, especially as the number of AI scrapers grows. Manual updates to accommodate every bot quickly become untenable.
For large crawlers like Googlebot and Bingbot, there is currently no way to differentiate between data used for traditional search engine indexing—where publishers and search engines have an implicit “agreement” based on citations to the original source—and data used to train or power generative AI products. This lack of granularity forces publishers into a difficult position, where blocking Googlebot or Bingbot entirely to prevent data usage for generative AI also hurts search engine results.
How HUMAN helps
HUMAN makes it easy to identify and manage AI-related traffic.
View and manage known AI bots. HUMAN uses a toggle on/off ‘known bots and crawlers’ list making it easy for organizations to make quick decisions on allowing, blocking, or request-limiting AI traffic. This adds a layer of enforcement to the manually updated and maintained robots.txt file while being easier to manage and track. HUMAN Scraping Defense will allow bots to access your application only if you have specifically allowed them to do so.
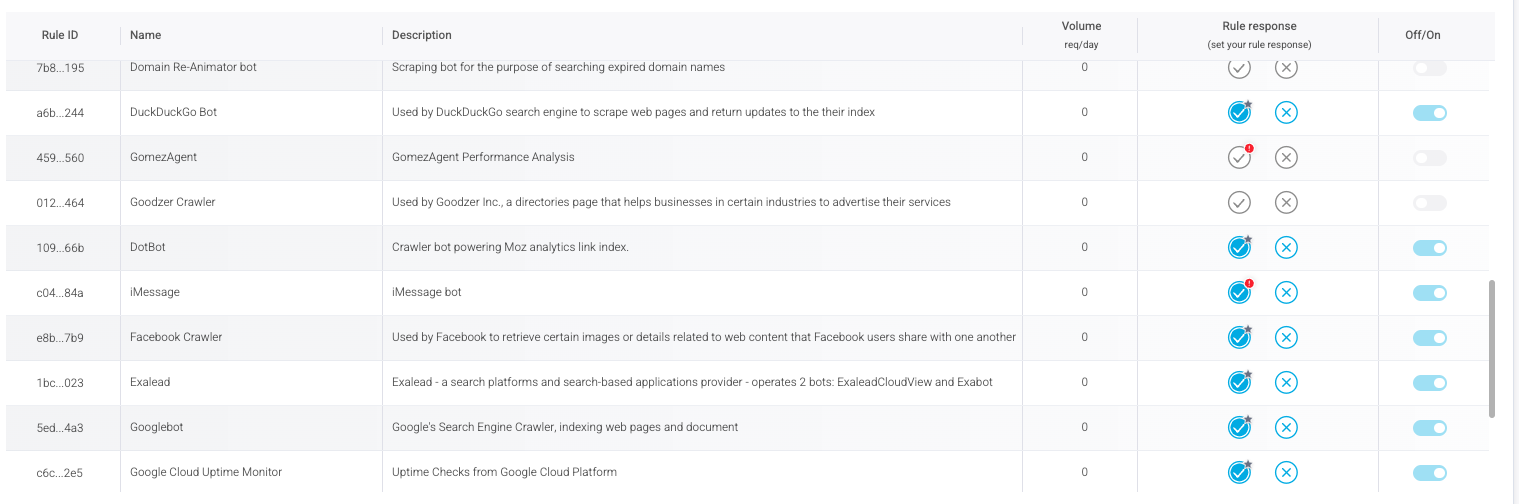
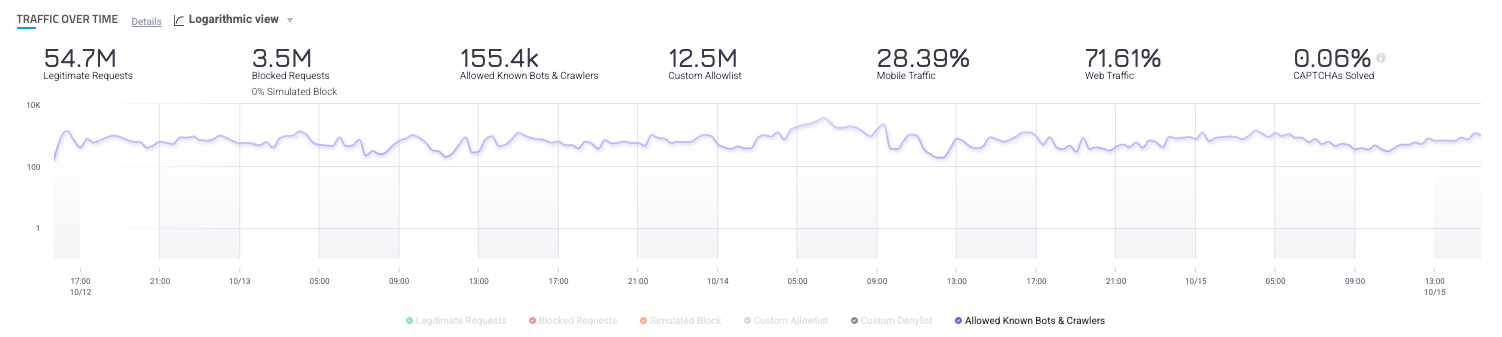
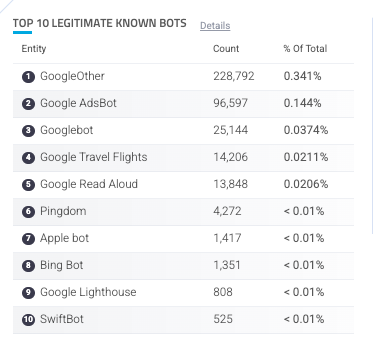
Provides visibility into AI bots. Traffic from known bots and crawlers is automatically highlighted in HUMAN activity dashboards and notifies you of the presence of new bots on your applications. It makes it easy for organizations to understand the volume of traffic hitting their applications and websites, as well as a granular breakdown of which bots are contributing to the traffic, and to what degree.
Analysts can dig in to understand which bots are accessing your content and what paths they are targeting, allowing you to monitor impacts and make informed decisions to protect your assets.
Blocks unknown, unwanted bots. HUMAN uses multiple techniques to identify and block unwanted bot traffic, including prior to the first request, making it exceptionally effective at stopping AI scrapers.
A combination of advanced machine learning (comprising predictive models and 400-plus algorithms), behavioral analysis, and intelligent fingerprinting is used to identify bots with exceptional accuracy. The solution then delivers optimal bot management, allowing organizations to choose how to manage AI bots – including hard blocks, honeypots, misdirection, or alternative content and pricing.
Effective strategies to combat AI-powered scraping
Scraping resulting from AI agents and LLMs is an increasingly challenging task for organizations to manage. Keeping an up-to-date robots.txt file is a strong first step to manage legitimate bots and crawlers. But for full control, a bot management solution is key. Organizations looking for a solution should select based on ability to control known bots and crawlers, depth of visibility into traffic and sophistication at detecting unwanted traffic.
Learn how HUMAN mitigates scraping bots on web and mobile applications, enabling full control over AI agents.