Late Night Confessions — Building a Website Using Rust, Rocket, Diesel, and Askama — Part 2
Read time: 14 minutesJohnny Tordgeman

This is part 2 in a three-part blog series. View part 1 here.
We previously left off with our server able to handle static content, but that is about all. In order to store and retrieve confessions, our app needs to interact with a database. That’s where Diesel comes to our aid!
⚠ In order for Diesel to interact with a database, a database instance needs to already exist. Make sure you have access to a Postgres instance (local or cloud based, both work) before moving forward.
Housekeeping
1. We begin with installing diesel_cli – a tool that helps us manage the database. As we only use Diesel for Postgres, we use the features flag to specify that:
cargo <span class="token function">install</span> diesel_cli --no-default-features --features postgres2. In the root folder of the project, create a .env file. At the top of the file add the DATABASE_URL property that Diesel will use to get the connection details of your Postgres instance.
<span class="token assign-left variable">DATABASE_URL</span><span class="token operator">=</span>postgres://<span class="token operator"><</span>user<span class="token operator">></span>:<span class="token operator"><</span>password<span class="token operator">></span>@<span class="token operator"><</span>ip<span class="token operator">></span>/confessions3. In the project root folder run diesel setup. Diesel will create a new database (confessions), as well as a set of empty migrations.
Using Migrations
With the database setup, it’s time to create the confessions table. Diesel uses a concept called migrations to track changes done to a database schema. You can think of migrations as a list of actions that you either apply to the database (up.sql) or revert (down.sql).
- Generate a new migration set for the confessions table by running the following command at the root of the project:
diesel migration generate confessions_tableThis creates a new folder inside of the migrations folder that holds the new migration set (up/down.sql) for the confessions table:

2. To create the new table, cd to the new migration folder and add the following to the up.sql file:
<span class="token comment">-- Your SQL goes here</span>
<span class="token keyword">CREATE</span> <span class="token keyword">TABLE</span> confessions <span class="token punctuation">(</span>
id <span class="token keyword">SERIAL</span> <span class="token keyword">PRIMARY</span> <span class="token keyword">KEY</span><span class="token punctuation">,</span>
confession <span class="token keyword">VARCHAR</span> <span class="token operator">NOT</span> <span class="token boolean">NULL</span>
<span class="token punctuation">)</span>3. In down.sql we specify how to revert the migration (i.e., dropping the confessions table):
<span class="token comment">-- This file should undo anything in `up.sql`</span>
<span class="token keyword">DROP</span> <span class="token keyword">TABLE</span> confessions4. Apply the new migration by running the following command:
diesel migration run To revert the last migration run diesel migration redo.
5. cd to the src folder to find a new file called schema.rs. This file contains the table definition created by Diesel that enables us to work with the database in a typesafe way.
With the housekeeping behind us, we proceed to establish a connection between our Rocket instance and Diesel.
Getting Connected
The first rule of working with a database is connecting to a database. A common method of connection between a database and an application is Connection Pool — a data structure that maintains active database connections (pool of connections) which the application can use at any point of time it needs.
Rocket, with its rocket_contrib crate (a crate that adds functionality commonly used by Rocket applications), allows us to easily set up a connection pool to our database using an ORM of our choice. In our case, that’s going to be Diesel.
1. We begin with adding three dependencies to our cargo.toml file: diesel, serde, and rocket_contrib:
<span class="token punctuation">[</span><span class="token table class-name">dependencies</span><span class="token punctuation">]</span>
<span class="token punctuation">.</span><span class="token punctuation">.</span><span class="token punctuation">.</span>
<span class="token key property">diesel</span> <span class="token punctuation">=</span> <span class="token punctuation">{</span> <span class="token key property">version</span> <span class="token punctuation">=</span> <span class="token string">"1.4.5"</span><span class="token punctuation">,</span> <span class="token key property">features</span> <span class="token punctuation">=</span> <span class="token punctuation">[</span><span class="token string">"postgres"</span><span class="token punctuation">]</span> <span class="token punctuation">}</span>
<span class="token key property">serde</span> <span class="token punctuation">=</span> <span class="token punctuation">{</span> <span class="token key property">version</span> <span class="token punctuation">=</span> <span class="token string">"1.0.123"</span><span class="token punctuation">,</span> <span class="token key property">features</span> <span class="token punctuation">=</span> <span class="token punctuation">[</span><span class="token string">"derive"</span><span class="token punctuation">]</span> <span class="token punctuation">}</span>
<span class="token punctuation">[</span><span class="token table class-name">dependencies.rocket_contrib</span><span class="token punctuation">]</span>
<span class="token key property">git</span> <span class="token punctuation">=</span> <span class="token string">"https://github.com/SergioBenitez/Rocket"</span>
<span class="token key property">version</span> <span class="token punctuation">=</span> <span class="token string">"0.5.0-dev"</span>
<span class="token key property">default-features</span> <span class="token punctuation">=</span> <span class="token boolean">false</span>
<span class="token key property">features</span><span class="token punctuation">=</span><span class="token punctuation">[</span><span class="token string">"json"</span><span class="token punctuation">,</span> <span class="token string">"diesel_postgres_pool"</span><span class="token punctuation">]</span> As we only need certain features from the above crates, we specify these features using the features property. In our case we only need Postgres support so we specify that in the features list for diesel and rocket_contrib.
2. Add the following import statements to your main.rs file:
<span class="token comment">#[macro_use]</span>
extern crate diesel;
use diesel::prelude::*;
use diesel::pg::PgConnection;
use rocket_contrib::databases::database;
use rocket_contrib::json::Json;
use serde::<span class="token punctuation">{</span>Deserialize<span class="token punctuation">,</span> Serialize<span class="token punctuation">}</span>;3. Next, we configure the connection settings for our database. Create a new file named Rocket.toml in the root folder of the project with the following content:
<span class="token punctuation">[</span><span class="token table class-name">global.databases</span><span class="token punctuation">]</span>
<span class="token key property">confessions_db</span> <span class="token punctuation">=</span> <span class="token punctuation">{</span> <span class="token key property">url</span> <span class="token punctuation">=</span> <span class="token string">"postgres://<user>:<password>@<ip>/confessions"</span> <span class="token punctuation">}</span>At this point you are probably thinking to yourself: “Johnny WTF? this is exactly the same connection string we configured earlier in the .env file. Can’t we just use that environmental variable and be done with it?”

Of course you can! But I’ll touch on how to do that a little bit later. For now, let’s roll with Rocket.toml.
4. Open your main.rs file and add a new unit-like struct called DBPool:
<span class="token attribute attr-name">#[database(<span class="token string">"confessions_db"</span>)]</span>
<span class="token keyword">pub</span> <span class="token keyword">struct</span> <span class="token type-definition class-name">DBPool</span><span class="token punctuation">(</span><span class="token class-name">PgConnection</span><span class="token punctuation">)</span><span class="token punctuation">;</span>The database attribute is used to bind a previously configured database to a poolable type in our application. The database attribute accepts the name of the database to bind as a single string parameter. This must match a database key configured in Rocket.toml. The macro will generate all the code needed on the decorated type to enable us to retrieve a connection from the database pool later on, or fail with an error.
5. Lastly we need to attach the database to our Rocket instance. We do that using the attach method of our Rocket instance. The attach method takes a fairing (think of that like a middleware) and attaches it to the request flow.
Append the attach method to the Rocket instance as follows:
<span class="token attribute attr-name">#[launch]</span>
<span class="token keyword">fn</span> <span class="token function-definition function">rocket</span><span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token punctuation">-></span> <span class="token class-name">Rocket</span> <span class="token punctuation">{</span>
<span class="token namespace">rocket<span class="token punctuation">::</span></span><span class="token function">ignite</span><span class="token punctuation">(</span><span class="token punctuation">)</span>
<span class="token punctuation">.</span><span class="token function">mount</span><span class="token punctuation">(</span><span class="token string">"/"</span><span class="token punctuation">,</span> <span class="token macro property">routes!</span><span class="token punctuation">[</span>root<span class="token punctuation">,</span> static_files<span class="token punctuation">]</span><span class="token punctuation">)</span>
<span class="token punctuation">.</span><span class="token function">attach</span><span class="token punctuation">(</span><span class="token class-name">DBPool</span><span class="token punctuation">::</span><span class="token function">fairing</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span>
<span class="token punctuation">}</span>Before we proceed, I’d like to take a quick (completely optional) detour and talk about how to use the connection string from the .env file instead of duplicating it with Rocket.toml. If you don’t feel like messing around with creating a database procedurally, feel free to skip over to the next section — Working With Models.
1. If created earlier, delete the Rocket.toml file from the root folder of the project.
2. dotenv is a crate that makes it super easy to work with environmental variables from a .env file. Add the dotenv crate as a dependency in your Cargo.toml file:
<span class="token punctuation">[</span><span class="token table class-name">dependencies</span><span class="token punctuation">]</span>
<span class="token punctuation">.</span><span class="token punctuation">.</span><span class="token punctuation">.</span>
<span class="token key property">dotenv</span> <span class="token punctuation">=</span> <span class="token string">"0.15.0"</span>3. In main.rs, refactor your rocket function as follows:
<span class="token attribute attr-name">#[launch]</span>
<span class="token keyword">fn</span> <span class="token function-definition function">rocket</span><span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token punctuation">-></span> <span class="token class-name">Rocket</span> <span class="token punctuation">{</span>
<span class="token function">dotenv</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">.</span><span class="token function">ok</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">;</span>
<span class="token keyword">let</span> db_url <span class="token operator">=</span> <span class="token namespace">env<span class="token punctuation">::</span></span><span class="token function">var</span><span class="token punctuation">(</span><span class="token string">"DATABASE_URL"</span><span class="token punctuation">)</span><span class="token punctuation">.</span><span class="token function">unwrap</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">;</span>
<span class="token keyword">let</span> db<span class="token punctuation">:</span> <span class="token class-name">Map</span><span class="token operator"><</span>_<span class="token punctuation">,</span> <span class="token class-name">Value</span><span class="token operator">></span> <span class="token operator">=</span> <span class="token macro property">map!</span> <span class="token punctuation">{</span>
<span class="token string">"url"</span> <span class="token operator">=></span> db_url<span class="token punctuation">.</span><span class="token function">into</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">,</span>
<span class="token string">"pool_size"</span> <span class="token operator">=></span> <span class="token number">10</span><span class="token punctuation">.</span><span class="token function">into</span><span class="token punctuation">(</span><span class="token punctuation">)</span>
<span class="token punctuation">}</span><span class="token punctuation">;</span>
<span class="token keyword">let</span> figment <span class="token operator">=</span> <span class="token namespace">rocket<span class="token punctuation">::</span></span><span class="token class-name">Config</span><span class="token punctuation">::</span><span class="token function">figment</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">.</span><span class="token function">merge</span><span class="token punctuation">(</span><span class="token punctuation">(</span><span class="token string">"databases"</span><span class="token punctuation">,</span> <span class="token macro property">map!</span><span class="token punctuation">[</span><span class="token string">"confessions_db"</span> <span class="token operator">=></span> db<span class="token punctuation">]</span><span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">;</span>
<span class="token namespace">rocket<span class="token punctuation">::</span></span><span class="token function">custom</span><span class="token punctuation">(</span>figment<span class="token punctuation">)</span>
<span class="token punctuation">.</span><span class="token function">mount</span><span class="token punctuation">(</span><span class="token string">"/"</span><span class="token punctuation">,</span> <span class="token macro property">routes!</span><span class="token punctuation">[</span>root<span class="token punctuation">,</span> static_files<span class="token punctuation">]</span><span class="token punctuation">)</span>
<span class="token punctuation">.</span><span class="token function">attach</span><span class="token punctuation">(</span><span class="token class-name">DBPool</span><span class="token punctuation">::</span><span class="token function">fairing</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span>
<span class="token punctuation">}</span>So what do we have here?
- Line 3: We call the
dotenvfunction (from the dotenv crate) to load variables found in the root folder .env file into Rust’s environment variables. - Line 5: Using Rust’s standard library we load up the value of the
DATABASE_URLvariable. - Lines 6–9: We define a
Mapthat holds two keys — url for the connection string andpool_sizefor the size of the connection pool. - Line 10: We create a Rocket config using Figment and add our database name (
confessions_db) as a key to thedatabasescollection. This closely resembles the Rocket.toml file and for a good reason — its basically the same thing just done programmatically instead of a toml formatted file. - Line 12: Instead of initializing the Rocket instance using
ignite, we use thecustommethod, passing on the Figment configuration object created on line 10.
—
Before moving on to creating the Database models, let’s build the project to make sure everything compiles as expected.
️ When I tried to compile the project on my Macbook, I got a compilation error related to Diesel stating that I’m missing libpq. If you happen to get the same, follow these steps:
1. Install libpq using homebrew: brew install libpq
2. In the project root folder create a new folder named .cargo and inside of it create a new file called config with the following content:
<span class="token comment"># for Apple Silicon Macs</span>
<span class="token punctuation">[</span>target.aarch64-apple-darwin<span class="token punctuation">]</span>
rustflags <span class="token operator">=</span> <span class="token punctuation">[</span><span class="token string">"-L"</span>, <span class="token string">"/opt/homebrew/opt/libpq/lib"</span><span class="token punctuation">]</span>
<span class="token comment"># for Intel Macs</span>
<span class="token punctuation">[</span>target.x86_64-apple-darwin<span class="token punctuation">]</span>
rustflags <span class="token operator">=</span> <span class="token punctuation">[</span><span class="token string">"-L"</span>, <span class="token string">"/usr/local/opt/libpq/lib"</span><span class="token punctuation">]</span>3. Run cargo build and enjoy.
Working With Models
To represent our database table in a type-safe way, we need to create a model (struct) that represents it. Think of a model as the link connecting your database table with your Rust code.
- In your src folder create a new file called models.rs. This file will be the home for the models we use in our project.
- We begin with the
Confessionmodel, which is used when querying the database. Add theConfessionstruct to models.rs:
<span class="token keyword">use</span> <span class="token keyword">crate</span><span class="token module-declaration namespace"><span class="token punctuation">::</span>schema<span class="token punctuation">::</span></span>confessions<span class="token punctuation">;</span>
<span class="token keyword">use</span> <span class="token namespace">serde<span class="token punctuation">::</span></span><span class="token punctuation">{</span><span class="token class-name">Serialize</span><span class="token punctuation">}</span><span class="token punctuation">;</span>
<span class="token attribute attr-name">#[derive(Queryable, Serialize)]</span>
<span class="token keyword">pub</span> <span class="token keyword">struct</span> <span class="token type-definition class-name">Confession</span> <span class="token punctuation">{</span>
<span class="token keyword">pub</span> id<span class="token punctuation">:</span> <span class="token keyword">i32</span><span class="token punctuation">,</span>
<span class="token keyword">pub</span> confession<span class="token punctuation">:</span> <span class="token class-name">String</span><span class="token punctuation">,</span>
<span class="token punctuation">}</span>Our struct looks identical to the Postgres table schema we created earlier (you can peek into schema.rs for a reminder on how it looks). But what is this Queryable attribute on top of it? It is a Diesel attribute that basically marks this struct as a READABLE result from the database. Under the hood, it will generate the code needed to load a result from a SQL query.
The order of the fields in the model matters! Make sure to define them in the same order as the table definition in schema.rs.
3. To save a confession to the database, we don’t need to specify the id property since it’s auto-incremented on the database side. For this reason, we will create an additional model in our models.rs file called NewConfession:
<span class="token attribute attr-name">#[derive(Insertable)]</span>
<span class="token attribute attr-name">#[table_name = <span class="token string">"confessions"</span>]</span>
<span class="token keyword">pub</span> <span class="token keyword">struct</span> <span class="token type-definition class-name">NewConfession</span><span class="token operator"><</span><span class="token lifetime-annotation symbol">'a</span><span class="token operator">></span> <span class="token punctuation">{</span>
<span class="token keyword">pub</span> confession<span class="token punctuation">:</span> <span class="token operator">&</span><span class="token lifetime-annotation symbol">'a</span> <span class="token keyword">str</span><span class="token punctuation">,</span>
<span class="token punctuation">}</span>We annotate this new model with the Insertable attribute so it can be used to INSERT data to our database. In addition, we also add the tablename_ attribute to specify which table this model is allowed to insert data to.
4. Lastly, we add the schema and models modules to main.rs:
<span class="token keyword">mod</span> <span class="token module-declaration namespace">models</span><span class="token punctuation">;</span>
<span class="token keyword">mod</span> <span class="token module-declaration namespace">schema</span><span class="token punctuation">;</span>Handling API Requests
It’s time to add a new route handler to our Rocket instance to handle POST requests containing new confessions.
1. In main.rs, add a new struct named ConfessionJSON, which represents the JSON data sent to us from the browser:
<span class="token keyword">use</span> <span class="token namespace">rocket_contrib<span class="token punctuation">::</span>json<span class="token punctuation">::</span></span><span class="token class-name">Json</span><span class="token punctuation">;</span>
<span class="token keyword">use</span> <span class="token namespace">serde<span class="token punctuation">::</span></span><span class="token punctuation">{</span><span class="token class-name">Deserialize</span><span class="token punctuation">,</span> <span class="token class-name">Serialize</span><span class="token punctuation">}</span><span class="token punctuation">;</span>
<span class="token keyword">use</span> <span class="token namespace">models<span class="token punctuation">::</span></span><span class="token punctuation">{</span><span class="token class-name">Confession</span><span class="token punctuation">,</span> <span class="token class-name">NewConfession</span><span class="token punctuation">}</span><span class="token punctuation">;</span>
<span class="token attribute attr-name">#[derive(Deserialize)]</span>
<span class="token keyword">struct</span> <span class="token type-definition class-name">ConfessionJSON</span> <span class="token punctuation">{</span>
content<span class="token punctuation">:</span> <span class="token class-name">String</span><span class="token punctuation">,</span>
<span class="token punctuation">}</span>2. Add a new struct named NewConfessionResponse which represents the JSON response we send back to the browser upon adding a new confession:
<span class="token attribute attr-name">#[derive(Serialize)]</span>
<span class="token keyword">struct</span> <span class="token type-definition class-name">NewConfessionResponse</span> <span class="token punctuation">{</span>
confession<span class="token punctuation">:</span> <span class="token class-name">Confession</span><span class="token punctuation">,</span>
<span class="token punctuation">}</span>3. Add a new POST route that will handle requests to /confession:
<span class="token keyword">mod</span> <span class="token module-declaration namespace">error</span><span class="token punctuation">;</span>
<span class="token keyword">use</span> <span class="token namespace">error<span class="token punctuation">::</span></span><span class="token class-name">CustomError</span><span class="token punctuation">;</span>
<span class="token keyword">use</span> <span class="token namespace">rocket<span class="token punctuation">::</span>response<span class="token punctuation">::</span>status<span class="token punctuation">::</span></span><span class="token class-name">Created</span><span class="token punctuation">;</span>
<span class="token attribute attr-name">#[post(<span class="token string">"/confession"</span>, format = <span class="token string">"json"</span>, data = <span class="token string">"<confession>"</span>)]</span>
<span class="token keyword">async</span> <span class="token keyword">fn</span> <span class="token function-definition function">post_confession</span><span class="token punctuation">(</span>
conn<span class="token punctuation">:</span> <span class="token class-name">DBPool</span><span class="token punctuation">,</span>
confession<span class="token punctuation">:</span> <span class="token class-name">Json</span><span class="token operator"><</span><span class="token class-name">ConfessionJSON</span><span class="token operator">></span><span class="token punctuation">,</span>
<span class="token punctuation">)</span> <span class="token punctuation">-></span> <span class="token class-name">Result</span><span class="token operator"><</span><span class="token class-name">Created</span><span class="token operator"><</span><span class="token class-name">Json</span><span class="token operator"><</span><span class="token class-name">NewConfessionResponse</span><span class="token operator">>></span><span class="token punctuation">,</span> <span class="token class-name">CustomError</span><span class="token operator">></span> <span class="token punctuation">{</span>
<span class="token punctuation">}</span>So what do we have here?
- Line 6: We define the route using three attributes:
– post — The HTTP verb this route is bound to.
– format — The required content type of the request. In our case we are going to useapplication/json. Any POST request to /confession which does not have a content type ofapplication/jsonwill NOT be routed to thepost_confessionhandler.
– data — The name of the variable the body will be bound to. In this example, I named the variableconfession(surrounded by < and >, which is a must), but you can name it anything you like, as long as you name it the same in the handler (line 2). - Lines 7–10: Here we define the handler for the /confession route. We pass
confessionas an argument (same variable from step 1’sdataattribute) and set its type asConfessionJSONwrapped by serde’sJsonattribute. Serde will deserialize the request body’s JSON payload as a Rust struct (ConfessionJSON) giving us a typesafe way to access it. In addition toconfessionwe get access to the database connection pool we created earlier, thanks to the attachment of it to our Rocket instance. - Line 10: The handler will return a
Resultcontaining either a JSON with an HTTP status of 201 (created) or an error (using a custom error that we will write next).
4. Add the implementation for the post_confession handler:
<span class="token punctuation">[</span><span class="token function">post</span><span class="token punctuation">(</span><span class="token string">"/confession"</span><span class="token punctuation">,</span> format <span class="token operator">=</span> <span class="token string">"json"</span><span class="token punctuation">,</span> data <span class="token operator">=</span> <span class="token string">"<confession>"</span><span class="token punctuation">)</span><span class="token punctuation">]</span>
<span class="token keyword">async</span> <span class="token keyword">fn</span> <span class="token function-definition function">post_confession</span><span class="token punctuation">(</span>
conn<span class="token punctuation">:</span> <span class="token class-name">DBPool</span><span class="token punctuation">,</span>
confession<span class="token punctuation">:</span> <span class="token class-name">Json</span><span class="token operator"><</span><span class="token class-name">ConfessionJSON</span><span class="token operator">></span><span class="token punctuation">,</span>
<span class="token punctuation">)</span> <span class="token punctuation">-></span> <span class="token class-name">Result</span><span class="token operator"><</span><span class="token class-name">Created</span><span class="token operator"><</span><span class="token class-name">Json</span><span class="token operator"><</span><span class="token class-name">NewConfessionResponse</span><span class="token operator">>></span><span class="token punctuation">,</span> <span class="token class-name">CustomError</span><span class="token operator">></span> <span class="token punctuation">{</span>
<span class="token keyword">let</span> new_confession<span class="token punctuation">:</span> <span class="token class-name">Confession</span> <span class="token operator">=</span> conn
<span class="token punctuation">.</span><span class="token function">run</span><span class="token punctuation">(</span><span class="token keyword">move</span> <span class="token closure-params"><span class="token closure-punctuation punctuation">|</span>c<span class="token closure-punctuation punctuation">|</span></span> <span class="token punctuation">{</span>
<span class="token namespace">diesel<span class="token punctuation">::</span></span><span class="token function">insert_into</span><span class="token punctuation">(</span><span class="token namespace">schema<span class="token punctuation">::</span>confessions<span class="token punctuation">::</span></span>table<span class="token punctuation">)</span>
<span class="token punctuation">.</span><span class="token function">values</span><span class="token punctuation">(</span><span class="token class-name">NewConfession</span> <span class="token punctuation">{</span>
confession<span class="token punctuation">:</span> <span class="token operator">&</span>confession<span class="token punctuation">.</span>content<span class="token punctuation">,</span>
<span class="token punctuation">}</span><span class="token punctuation">)</span>
<span class="token punctuation">.</span><span class="token function">get_result</span><span class="token punctuation">(</span>c<span class="token punctuation">)</span>
<span class="token punctuation">}</span><span class="token punctuation">)</span>
<span class="token punctuation">.</span><span class="token keyword">await</span><span class="token operator">?</span><span class="token punctuation">;</span>
<span class="token keyword">let</span> response <span class="token operator">=</span> <span class="token class-name">NewConfessionResponse</span> <span class="token punctuation">{</span>
confession<span class="token punctuation">:</span> new_confession<span class="token punctuation">,</span>
<span class="token punctuation">}</span><span class="token punctuation">;</span>
<span class="token class-name">Ok</span><span class="token punctuation">(</span><span class="token class-name">Created</span><span class="token punctuation">::</span><span class="token function">new</span><span class="token punctuation">(</span><span class="token string">"/confession"</span><span class="token punctuation">)</span><span class="token punctuation">.</span><span class="token function">body</span><span class="token punctuation">(</span><span class="token class-name">Json</span><span class="token punctuation">(</span>response<span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">)</span>
<span class="token punctuation">}</span>Now this handler might seem scary ( ) in its current form, so let’s break it into smaller chunks:
- Lines 6–14: We create a new confession by calling the run method on our connection pool using Diesel’s
insert_intomethod. The method takes the table name as the first argument and then using thevaluesmethod we pass a struct (of typeNewConfessionas that is ourInsertablestruct) with the data that needs to be saved. Finally, we callawaiton therunmethod as it is an asynchronous function. - Lines 16–18: We create a new
NewConfessionResponsewith the result of the insert item query (thenew_confessionvariable). - Line 20: We return a
Resultwith the newly created confession, wrapped withCreatedto return a status code of 201.
5. If post_confession fails for whatever reason, it returns a CustomError error, that we need to create next. Inside the src folder, create a new file called error.rs and add the following content:
<span class="token keyword">use</span> <span class="token namespace">failure<span class="token punctuation">::</span></span><span class="token class-name">Fail</span><span class="token punctuation">;</span>
<span class="token keyword">use</span> <span class="token namespace">rocket<span class="token punctuation">::</span>http<span class="token punctuation">::</span></span><span class="token punctuation">{</span><span class="token class-name">ContentType</span><span class="token punctuation">,</span> <span class="token class-name">Status</span><span class="token punctuation">}</span><span class="token punctuation">;</span>
<span class="token keyword">use</span> <span class="token namespace">rocket<span class="token punctuation">::</span>response<span class="token punctuation">::</span></span><span class="token punctuation">{</span><span class="token class-name">Responder</span><span class="token punctuation">,</span> <span class="token class-name">Response</span><span class="token punctuation">,</span> <span class="token class-name">Result</span><span class="token punctuation">}</span><span class="token punctuation">;</span>
<span class="token keyword">use</span> <span class="token namespace">rocket<span class="token punctuation">::</span></span><span class="token class-name">Request</span><span class="token punctuation">;</span>
<span class="token keyword">use</span> <span class="token namespace">std<span class="token punctuation">::</span>io<span class="token punctuation">::</span></span><span class="token class-name">Cursor</span><span class="token punctuation">;</span>
<span class="token attribute attr-name">#[derive(Debug, Fail)]</span>
<span class="token keyword">pub</span> <span class="token keyword">enum</span> <span class="token type-definition class-name">CustomError</span> <span class="token punctuation">{</span>
<span class="token attribute attr-name">#[fail(display = <span class="token string">"Database Error {}"</span>, 0)]</span>
<span class="token class-name">DatabaseErr</span><span class="token punctuation">(</span><span class="token namespace">diesel<span class="token punctuation">::</span>result<span class="token punctuation">::</span></span><span class="token class-name">Error</span><span class="token punctuation">)</span><span class="token punctuation">,</span>
<span class="token punctuation">}</span>
<span class="token keyword">impl</span> <span class="token class-name">From</span><span class="token operator"><</span><span class="token namespace">diesel<span class="token punctuation">::</span>result<span class="token punctuation">::</span></span><span class="token class-name">Error</span><span class="token operator">></span> <span class="token keyword">for</span> <span class="token class-name">CustomError</span> <span class="token punctuation">{</span>
<span class="token keyword">fn</span> <span class="token function-definition function">from</span><span class="token punctuation">(</span>e<span class="token punctuation">:</span> <span class="token namespace">diesel<span class="token punctuation">::</span>result<span class="token punctuation">::</span></span><span class="token class-name">Error</span><span class="token punctuation">)</span> <span class="token punctuation">-></span> <span class="token keyword">Self</span> <span class="token punctuation">{</span>
<span class="token class-name">CustomError</span><span class="token punctuation">::</span><span class="token class-name">DatabaseErr</span><span class="token punctuation">(</span>e<span class="token punctuation">)</span>
<span class="token punctuation">}</span>
<span class="token punctuation">}</span>
<span class="token keyword">impl</span><span class="token operator"><</span><span class="token lifetime-annotation symbol">'r</span><span class="token operator">></span> <span class="token class-name">Responder</span><span class="token operator"><</span><span class="token lifetime-annotation symbol">'r</span><span class="token punctuation">,</span> <span class="token lifetime-annotation symbol">'static</span><span class="token operator">></span> <span class="token keyword">for</span> <span class="token class-name">CustomError</span> <span class="token punctuation">{</span>
<span class="token keyword">fn</span> <span class="token function-definition function">respond_to</span><span class="token punctuation">(</span><span class="token keyword">self</span><span class="token punctuation">,</span> _<span class="token punctuation">:</span> <span class="token operator">&</span><span class="token lifetime-annotation symbol">'r</span> <span class="token class-name">Request</span><span class="token operator"><</span><span class="token lifetime-annotation symbol">'_</span><span class="token operator">></span><span class="token punctuation">)</span> <span class="token punctuation">-></span> <span class="token class-name">Result</span><span class="token operator"><</span><span class="token lifetime-annotation symbol">'static</span><span class="token operator">></span> <span class="token punctuation">{</span>
<span class="token keyword">let</span> body <span class="token operator">=</span> <span class="token macro property">format!</span><span class="token punctuation">(</span><span class="token string">"Diesel error: {}"</span><span class="token punctuation">,</span> <span class="token keyword">self</span><span class="token punctuation">)</span><span class="token punctuation">;</span>
<span class="token keyword">let</span> res <span class="token operator">=</span> <span class="token class-name">Response</span><span class="token punctuation">::</span><span class="token function">build</span><span class="token punctuation">(</span><span class="token punctuation">)</span>
<span class="token punctuation">.</span><span class="token function">status</span><span class="token punctuation">(</span><span class="token class-name">Status</span><span class="token punctuation">::</span><span class="token class-name">InternalServerError</span><span class="token punctuation">)</span>
<span class="token punctuation">.</span><span class="token function">header</span><span class="token punctuation">(</span><span class="token class-name">ContentType</span><span class="token punctuation">::</span><span class="token class-name">Plain</span><span class="token punctuation">)</span>
<span class="token punctuation">.</span><span class="token function">sized_body</span><span class="token punctuation">(</span>body<span class="token punctuation">.</span><span class="token function">len</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">,</span> <span class="token class-name">Cursor</span><span class="token punctuation">::</span><span class="token function">new</span><span class="token punctuation">(</span>body<span class="token punctuation">)</span><span class="token punctuation">)</span>
<span class="token punctuation">.</span><span class="token function">finalize</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">;</span>
<span class="token class-name">Ok</span><span class="token punctuation">(</span>res<span class="token punctuation">)</span>
<span class="token punctuation">}</span>
<span class="token punctuation">}</span>I won’t go into much detail on what’s happening here, but the main takeaways from this file are:
- We create an
enumto hold different error types and decorate it using Failure’sFailattribute (lines 7–11). - We implement the
Fromtrait so we can support the diesel error type (lines 13–17). - Rocket requires the response of a handler (be it an error or a valid response) to implement the
Respondertrait. We implement this trait on ourCustomErrorto display an error (ofdiesel::result::Error) to the caller (lines 19–28).
6. Our post_confession handler is now completed . Let’s mount it to our Rocket instance’s routes with a new base of /api:
<span class="token attribute attr-name">#[launch]</span>
<span class="token keyword">fn</span> <span class="token function-definition function">rocket</span><span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token punctuation">-></span> <span class="token class-name">Rocket</span> <span class="token punctuation">{</span>
<span class="token namespace">rocket<span class="token punctuation">::</span></span><span class="token function">ignite</span><span class="token punctuation">(</span><span class="token punctuation">)</span>
<span class="token punctuation">.</span><span class="token function">mount</span><span class="token punctuation">(</span><span class="token string">"/"</span><span class="token punctuation">,</span> <span class="token macro property">routes!</span><span class="token punctuation">[</span>root<span class="token punctuation">,</span> static_files<span class="token punctuation">]</span><span class="token punctuation">)</span>
<span class="token punctuation">.</span><span class="token function">mount</span><span class="token punctuation">(</span><span class="token string">"/api"</span><span class="token punctuation">,</span> <span class="token macro property">routes!</span><span class="token punctuation">[</span>post_confession<span class="token punctuation">]</span><span class="token punctuation">)</span>
<span class="token punctuation">.</span><span class="token function">attach</span><span class="token punctuation">(</span><span class="token class-name">DBPool</span><span class="token punctuation">::</span><span class="token function">fairing</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span>
<span class="token punctuation">}</span>
<span class="token attribute attr-name">#[derive(Serialize)]</span>
<span class="token keyword">struct</span> <span class="token type-definition class-name">NewConfessionResponse</span> <span class="token punctuation">{</span>
confession<span class="token punctuation">:</span> <span class="token class-name">Confession</span><span class="token punctuation">,</span>
<span class="token punctuation">}</span>7. We are finally ready to test our new API! Run the app with cargo run and on a different terminal run the following curl:
<span class="token function">curl</span> -X POST http://localhost:8000/api/confession -H <span class="token string">"Content-Type: application/json"</span> -d <span class="token string">'{"content": "I am in love with the girl next door" }'</span>If all went well you should get back a JSON response with the confession and its new ID.

That was quite a ride, wasn’t it? You’d be happy to know (or not) that adding the GET route — for getting a random confession out of Postgres — is a much simpler task:
1. Add the new get_confession handler to main.rs:
<span class="token macro property">no_arg_sql_function!</span><span class="token punctuation">(</span><span class="token constant">RANDOM</span><span class="token punctuation">,</span> <span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">,</span> <span class="token string">"Represents the sql RANDOM() function"</span><span class="token punctuation">)</span><span class="token punctuation">;</span>
<span class="token attribute attr-name">#[get(<span class="token string">"/confession"</span>, format = <span class="token string">"json"</span>)]</span>
<span class="token keyword">async</span> <span class="token keyword">fn</span> <span class="token function-definition function">get_confession</span><span class="token punctuation">(</span>conn<span class="token punctuation">:</span> <span class="token class-name">DBPool</span><span class="token punctuation">)</span> <span class="token punctuation">-></span> <span class="token class-name">Result</span><span class="token operator"><</span><span class="token class-name">Json</span><span class="token operator"><</span><span class="token class-name">Confession</span><span class="token operator">></span><span class="token punctuation">,</span> <span class="token class-name">CustomError</span><span class="token operator">></span> <span class="token punctuation">{</span>
<span class="token keyword">let</span> confession<span class="token punctuation">:</span> <span class="token class-name">Confession</span> <span class="token operator">=</span> conn
<span class="token punctuation">.</span><span class="token function">run</span><span class="token punctuation">(</span><span class="token closure-params"><span class="token closure-punctuation punctuation">|</span>c<span class="token closure-punctuation punctuation">|</span></span> <span class="token punctuation">{</span>
<span class="token namespace">schema<span class="token punctuation">::</span>confessions<span class="token punctuation">::</span></span>table
<span class="token punctuation">.</span><span class="token function">order</span><span class="token punctuation">(</span><span class="token constant">RANDOM</span><span class="token punctuation">)</span>
<span class="token punctuation">.</span><span class="token function">limit</span><span class="token punctuation">(</span><span class="token number">1</span><span class="token punctuation">)</span>
<span class="token punctuation">.</span><span class="token function">first</span><span class="token punctuation">::</span><span class="token operator"><</span><span class="token class-name">Confession</span><span class="token operator">></span><span class="token punctuation">(</span>c<span class="token punctuation">)</span>
<span class="token punctuation">}</span><span class="token punctuation">)</span>
<span class="token punctuation">.</span><span class="token keyword">await</span><span class="token operator">?</span><span class="token punctuation">;</span>
<span class="token class-name">Ok</span><span class="token punctuation">(</span><span class="token class-name">Json</span><span class="token punctuation">(</span>confession<span class="token punctuation">)</span><span class="token punctuation">)</span>
<span class="token punctuation">}</span>Nothing really exciting happening here. We get a connection from the pool (line 5), use the confessions table (line 7) to query for a single random confession (line 1 defines the SQL’s RANDOM function, lines 8–10 build the query) and eventually returning a JSON of the confession (line 14).
2. Mount the new get_confession handler to our Rocket instance’s routes:
<span class="token attribute attr-name">#[launch]</span>
<span class="token keyword">fn</span> <span class="token function-definition function">rocket</span><span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token punctuation">-></span> <span class="token class-name">Rocket</span> <span class="token punctuation">{</span>
<span class="token namespace">rocket<span class="token punctuation">::</span></span><span class="token function">ignite</span><span class="token punctuation">(</span><span class="token punctuation">)</span>
<span class="token punctuation">.</span><span class="token function">mount</span><span class="token punctuation">(</span><span class="token string">"/"</span><span class="token punctuation">,</span> <span class="token macro property">routes!</span><span class="token punctuation">[</span>root<span class="token punctuation">,</span> static_files<span class="token punctuation">]</span><span class="token punctuation">)</span>
<span class="token punctuation">.</span><span class="token function">mount</span><span class="token punctuation">(</span><span class="token string">"/api"</span><span class="token punctuation">,</span> <span class="token macro property">routes!</span><span class="token punctuation">[</span>post_confession<span class="token punctuation">,</span> get_confession<span class="token punctuation">]</span><span class="token punctuation">)</span>
<span class="token punctuation">.</span><span class="token function">attach</span><span class="token punctuation">(</span><span class="token class-name">DBPool</span><span class="token punctuation">::</span><span class="token function">fairing</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span>
<span class="token punctuation">}</span>3. Launch with cargo run and in another terminal window run this lovely curl:
<span class="token function">curl</span> http://localhost:8000/api/confession -H <span class="token string">"Content-Type: application/json"</span>Now, what is it that we got back? A random confession from Postgres that’s what!
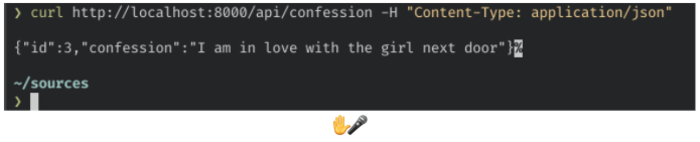
And with that our API is completed. We have a Rocket web server running with two API endpoints (post and get confessions) and an additional route to handle static content. Let’s move on to the final task for our website — adding the presentation layer.